
Shenzhen University

My current research focuses on medical Multimodal Large Language Models (MLLMs), under the supervision of Prof. Wang Benyou. I have contributed to leading medical AI systems such as HuatuoGPT-o1 and ShizhenGPT. I am also an active open-source contributor, participating in projects on medical multimodal generation and image–text alignment, such as MedGen and Sharegpt-4o-image.
I am seeking PhD opportunities or a full-time role and would appreciate the chance to connect.Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Shenzhen UniversityControl Science and Engineering
Shenzhen UniversityControl Science and Engineering
M.S. Student
Released more than five papersSept. 2023 - present -
 Guangzhou UniversityRobotics Engineering
Guangzhou UniversityRobotics Engineering
B.S. Student
Rank: 5/81(Top 6%)Sept. 2019 - Jul. 2023
Experience
-
 Freedom Intelligence Lab, CUHK-SZResearch Assistant (RA)Aug. 2024 - Present
Freedom Intelligence Lab, CUHK-SZResearch Assistant (RA)Aug. 2024 - Present
Honors & Awards
-
AIMO-2-Gold Mendal2025
-
Master's Scholarship2025
-
National Scholarship2022
-
Academic Excellence Award2022
-
Outstanding Contributor Award2022
-
Undergraduate Scholarship2022
News
Selected Publications (view all )
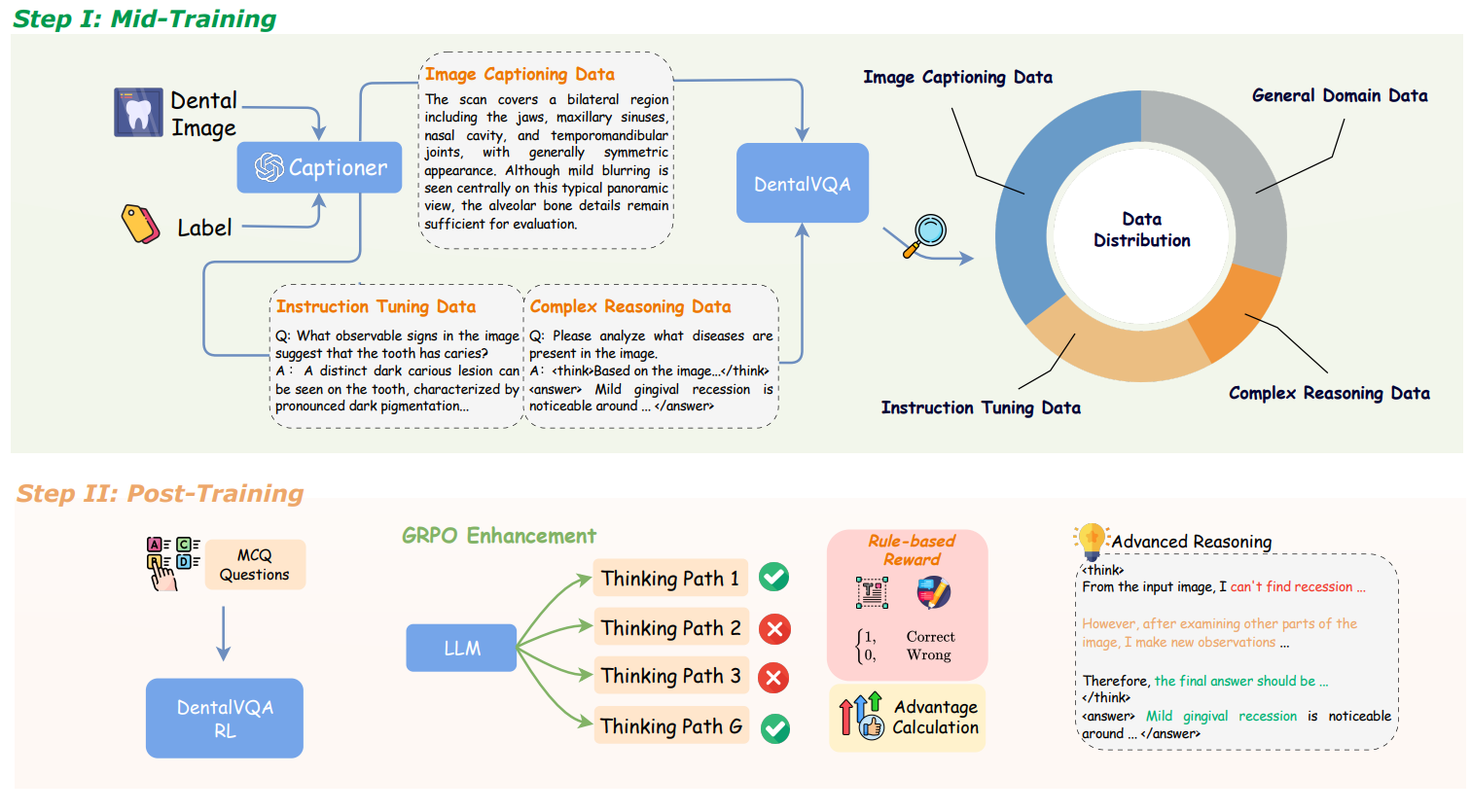
DentalGPT: Incentivizing Complex Multi-modal Diagnosis in Dentistry
Zhenyang Cai, Jiaming Zhang, Junjie Zhao, Ziyi Zeng, Yanchao Li, Jingyi Liang, Junying Chen, Yunjin Yang, Jiajun You, Shuzhi Deng, Tongfei Wang, Wanting Chen, Chunxiu Hao, Ruiqi Xie, Zhenwei Wen, Xiangyi Feng, Zou Ting, Jin Zou Lin, Jianquan Li, Liangyi Chen, Junwen Wang, Shan Jiang, Benyou Wang
Under review. 2025
This work presents DentalGPT, a 7B dental-specific multimodal model developed through high-quality domain data and staged training. Using DentalVQA, the largest annotated dental image dataset, together with GRPO-based post-training, the model achieves state-of-the-art results in dental disease classification and VQA, showing the effectiveness of targeted domain adaptation.
DentalGPT: Incentivizing Complex Multi-modal Diagnosis in Dentistry
Zhenyang Cai, Jiaming Zhang, Junjie Zhao, Ziyi Zeng, Yanchao Li, Jingyi Liang, Junying Chen, Yunjin Yang, Jiajun You, Shuzhi Deng, Tongfei Wang, Wanting Chen, Chunxiu Hao, Ruiqi Xie, Zhenwei Wen, Xiangyi Feng, Zou Ting, Jin Zou Lin, Jianquan Li, Liangyi Chen, Junwen Wang, Shan Jiang, Benyou Wang
Under review. 2025
This work presents DentalGPT, a 7B dental-specific multimodal model developed through high-quality domain data and staged training. Using DentalVQA, the largest annotated dental image dataset, together with GRPO-based post-training, the model achieves state-of-the-art results in dental disease classification and VQA, showing the effectiveness of targeted domain adaptation.
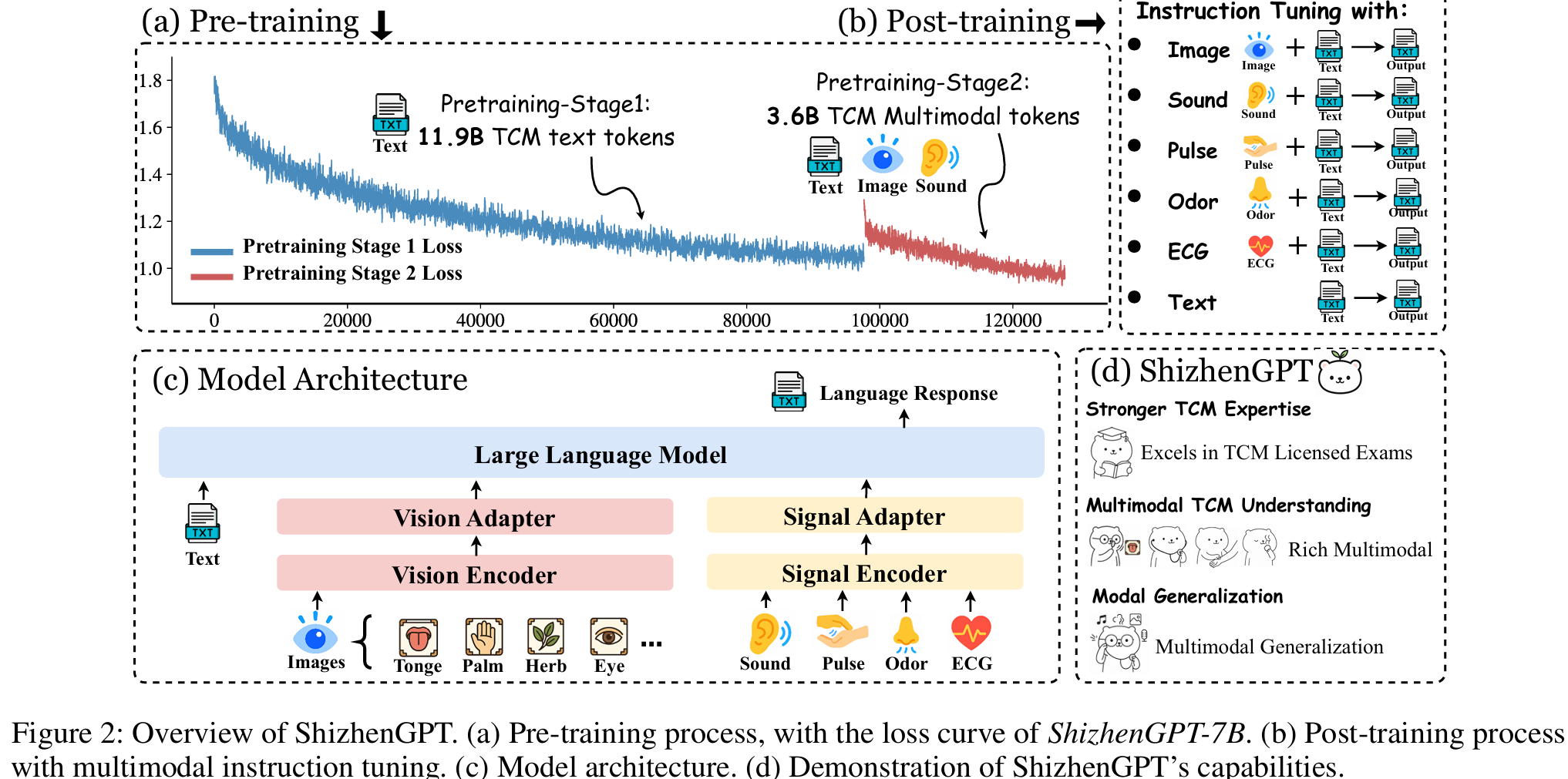
ShizhenGPT: Towards Multimodal LLMs for Traditional Chinese Medicine
Junying Chen, Zhenyang Cai, Zhiheng Liu, Yunjin Yang, Rongsheng Wang, Qingying Xiao, Xiangyi Feng, Zhan Su, Jing Guo, Xiang Wan, Guangjun Yu, Haizhou Li, Benyou Wang
Under review. 2025
This work introduces ShizhenGPT, the first multimodal large language model for Traditional Chinese Medicine (TCM), addressing data scarcity and the inherently multimodal nature of TCM diagnostics. We curate the largest TCM dataset to date (300GB+ across text, images, audio, and physiological signals) and evaluate the model using national TCM qualification exams and a new visual diagnosis benchmark. Experiments show that ShizhenGPT surpasses comparable LLMs and achieves state-of-the-art multimodal perception across pulse, smell, sound, and vision, paving the way for holistic TCM diagnostic intelligence.
ShizhenGPT: Towards Multimodal LLMs for Traditional Chinese Medicine
Junying Chen, Zhenyang Cai, Zhiheng Liu, Yunjin Yang, Rongsheng Wang, Qingying Xiao, Xiangyi Feng, Zhan Su, Jing Guo, Xiang Wan, Guangjun Yu, Haizhou Li, Benyou Wang
Under review. 2025
This work introduces ShizhenGPT, the first multimodal large language model for Traditional Chinese Medicine (TCM), addressing data scarcity and the inherently multimodal nature of TCM diagnostics. We curate the largest TCM dataset to date (300GB+ across text, images, audio, and physiological signals) and evaluate the model using national TCM qualification exams and a new visual diagnosis benchmark. Experiments show that ShizhenGPT surpasses comparable LLMs and achieves state-of-the-art multimodal perception across pulse, smell, sound, and vision, paving the way for holistic TCM diagnostic intelligence.
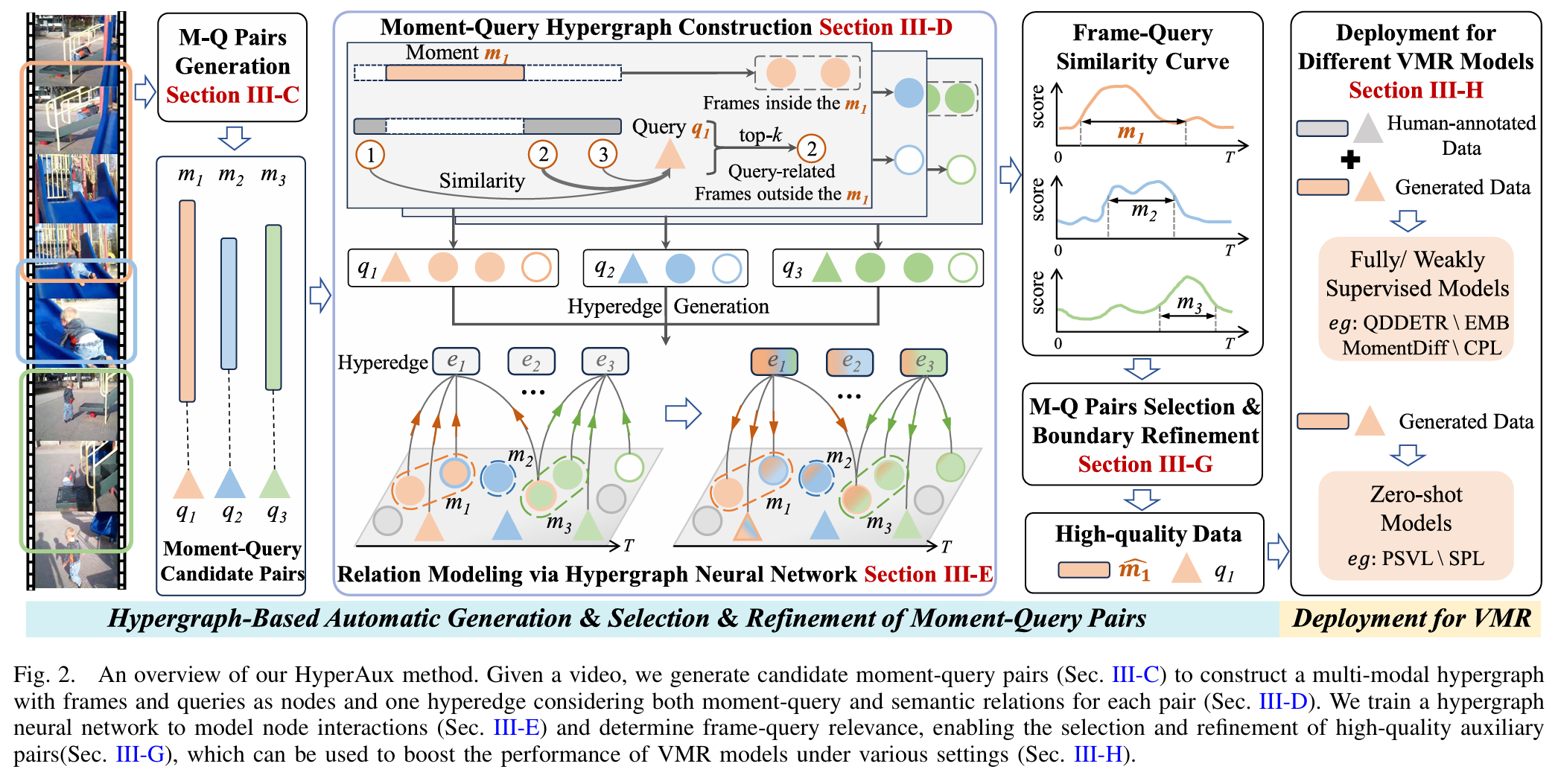
Improving Video Moment Retrieval by Auxiliary Moment-Query Pairs With Hyper-Interaction
Runhao Zeng, Yishen Zhuo, Jialiang Li, Yunjin Yang, Huisi Wu, Qi Chen, Xiping Hu, Victor C. M. Leung
IEEE Transactions on Circuits and Systems for Video Technology 2025 Accepted
This work introduces HyperAux, a hypergraph-based framework that enriches video moment retrieval (VMR) training data by generating and selecting high-quality moment–query pairs. By modeling multi-modal hyper-interactions among frames and queries, HyperAux produces context-aware representations that refine moment boundaries and improve pair selection. Without requiring human annotations, it leverages semantic discrepancies inside and outside moments to guide training. The resulting auxiliary data boosts twelve VMR models across fully-supervised, weakly-supervised, and zero-shot settings on ActivityNet Captions, Charades-STA, and QVHighlights.
Improving Video Moment Retrieval by Auxiliary Moment-Query Pairs With Hyper-Interaction
Runhao Zeng, Yishen Zhuo, Jialiang Li, Yunjin Yang, Huisi Wu, Qi Chen, Xiping Hu, Victor C. M. Leung
IEEE Transactions on Circuits and Systems for Video Technology 2025 Accepted
This work introduces HyperAux, a hypergraph-based framework that enriches video moment retrieval (VMR) training data by generating and selecting high-quality moment–query pairs. By modeling multi-modal hyper-interactions among frames and queries, HyperAux produces context-aware representations that refine moment boundaries and improve pair selection. Without requiring human annotations, it leverages semantic discrepancies inside and outside moments to guide training. The resulting auxiliary data boosts twelve VMR models across fully-supervised, weakly-supervised, and zero-shot settings on ActivityNet Captions, Charades-STA, and QVHighlights.